기계학습(MACHINE LEARNING) 기본
작성자 정보
- ◆딥셀◆ 작성
- 작성일
컨텐츠 정보
- 9,038 조회
본문
머신러닝
현재 인공지능 기술의 대부분을 차지하는 머신러닝(또는 기계학습)에 대해 간단하게 알아보겠습니다.
학습: 컴퓨터는 무엇을 어떻게 학습한다는 것일까?
학습을 한다는 것은 자료를 통해서 새로운 것을 알아간다는 의미입니다. 그러나 학습이라는 용어를 붙인 컴퓨터에서 일어나는 동작은 사람이 배우는 것과는 다릅니다. 이를 제대로 이해하기 위해서는 컴퓨터의 능력을 알아야 합니다. 컴퓨터가 처리하는 모든 데이터는 숫자여야 합니다. 우리가 컴퓨터를 통해 보는 다양한 멀티미디어 데이터들도 모두 컴퓨터에서 처리될 때는 숫자로 변환된 상태에서 처리가 됩니다. 그리고 숫자 데이터를 처리한다고 하는 것은 결국 계산을 하는 것입니다. 컴퓨터의 능력을 숫자 데이터를 계산하는 것뿐이라고 이해하는 것이 모든 소프트웨어를 이해하는 데 있어서 아주 중요합니다. 다만 컴퓨터는 숫자 계산을 매우 빠르고 정확하게 할 수 있습니다. 컴퓨터의 탁월한 능력은 여기에서 나옵니다.
그리고 한 단계 더 나아가 알아야 할 내용은 복잡한 계산을 모듈화해서 처리할 때 함수를 쓴다는 것입니다. 소프트웨어에서 함수는 수학에서의 함수와 비슷합니다. 입력 값을 받아서 여러가지 규칙에 따라 계산을 하여 결과를 출력하는 프로그램 단위를 함수라고 합니다. 수학에서 나오는 함수도 독립변수 값을 주면 주어진 규칙에 따라 종속변수를 계산해 냅니다. 소프트웨어에서의 함수도 비슷하게 일을 합니다. 함수의 내용은 수학에서 계산의 규칙을 수식으로 쓴 것처럼 프로그램 언어로 계산의 규칙을 쓰면 됩니다.
함수의 계산식을 보면 입력값으로 대체되는 부분과 고정된 부분으로 나누어 집니다. 수학에서는 고정된 값들을 계수(Coefficient)라고 합니다. 아래의 식에서 a, b, c가 계수입니다.
$$ f(x) = ax^2 + bx + c $$
위 식은 변수 x에 대한 2차 함수입니다. 여기에서 계수 a, b, c의 값이 정해지면 함수 f(x)는 결정이 되고 입력으로 주어지는 x의 값에 따라 출력값을 만들어 줍니다. 기계학습에서 학습한다는 말의 의미는 위와 같은 함수의 모양이 주어졌을 때, 계수 a, b, c의 값을 점점 개선한다는 의미입니다.
그렇다면 어떻게 학습을 할까요? 이 질문은 어떻게 계수의 값을 점점 더 좋은 것으로 개선하는가? 라는 질문과 같습니다. 이 과정에 대한 내용은 수학적으로 복잡합니다. 그래서 수학적인 내용 없이 간략하게 개념만을 알아보겠습니다.
우선 학습을 하기 위해서는 데이터셋(Dataset)이 필요합니다. 데이터셋이란 여러개의 입력데이터와 출력값을 함께 갖는 데이터의 모음입니다. 여기서 중요한 것은 정확한 출력값이 입력값과 짝지어저 있어야 한다는 것입니다. 그리고 이렇게 짝지어진 데이터가 충분히 많이 모여 있어야 합니다.
기계학습에서 학습은 이 데이터셋을 가지고 다음과 같은 방식으로 진행이 됩니다.
- 계수 초기화
- 초기화된 계수와 입력데이터를 가지고 출력값을 계산
- 이렇게 계산해서 구한 출력값과 데이터셋에서 가지고 있던 출력값을 비교
- 이 두 값의 차이를 줄이는 쪽으로 계수들을 수정(개선)
- 새로 개선된 계수와 입력값을 가지고 출력값을 계산
- 데이터셋에서 가지고 있던 출력값과 비교
- 이러한 절차를 많은 데이터셋에 대하여 반복적으로 시행
이렇게 데이터셋을 가지고 계산을 반복하며 계수값을 개선해 나가는 것이 기계학습에서의 학습의 의미입니다. 전체적으로 다시 한 번 정리해보면 기계학습은 다음과 같습니다.
- 데이터를 계산할 함수의 모양을 만든다.(계수는 정해지지 않았음)
- 데이터셋을 가지고 계산을 반복하며 좋은 계수값을 찾아 나간다.(계수 개선 과정)
- 가장 좋은 계수값을 찾아서 함수를 완성시킨다.(계수 결정)
이 것이 수학을 최대한 배재하고 설명한 기계학습의 내용입니다.
기계학습은 알고리즘이다.
위에서 컴퓨터 프로그래밍이나 수학적인 배경이 약한 사람들도 이해할 수 있을 정도로 기계학습이 무엇인지 간단하게 알아보았습니다. 기계학습에 대해 조금 더 학문적으로 알아보겠습니다. 위키백과를 보면 ‘1959년, 아서 사무엘은 기계 학습을 “기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야"라고 정의하였다.‘라는 문장이 있습니다. 여기에서 코드로 명시하지 않은 부분을 확정되지 않은 계수라고 생각하셔도 됩니다. 그리고 데이터로부터 학습하여 좋은 계수값을 찾는 알고리즘을 찾는 것이 기계학습이라는 연구 분야라고 생각하면 될 것 같습니다. 기계학습은 더 좋은 알고리즘을 찾는 연구 분야이므로 많은 종류의 알고리즘을 찾고 연구하여 왔습니다. 그 중에서 좋은 결과를 내며 많이 사용되어 온 알고리즘들에는 다음과 같은 것들이 있습니다.
- 서포트 벡터 머신(SVM ; Support Vector Machine)
- 의사결정 나무(Decision Tree)
- 추천 시스템(Recommender system)
- XGBoost
- LightGBM
- 인공신경망(Artificial Neural Network)
이렇게 기계학습에는 다양한 종류의 알고리즘과 방법들이 존재하며 각각 특징과 장단점을 가지므로 적용 분야나 주어진 데이터셋에 따라 적합한 알고리즘으로 인공지능 시스템을 만들 수 있습니다.
다른 프로그래밍 방식과의 차이
컴퓨터에서 실행되는 소프트웨어를 만들기위해 프로그래밍을 합니다. 좋은 소프트웨어를 만드는 방법을 찾기 위해 많은 연구들이 있었고, 그 결과로 많은 소프트웨어 개발 방법들과 알고리즘들이 나오게 되었습니다. 기계학습도 컴퓨터 소프트웨어를 만드는 방법 중의 하나입니다. 그리고 기계학습의 두드러진 특징은 프로그램의 작동 규칙을 모두 코드로 명확하게 정하지 않고 코드의 일부(계수에 해당하는 값)를 데이터를 가지고 학습을 하여 정한다는 것입니다. 이 것을 기존의 다른 프로그래밍 방식과 비교하여 조금 더 알아보겠습니다.
보통의 전통적인 프로그래밍 방식은 입력된 데이터를 처리하는 규칙을 모두 사람이 정하여 코드에 명확하게 지정하는 것입니다.
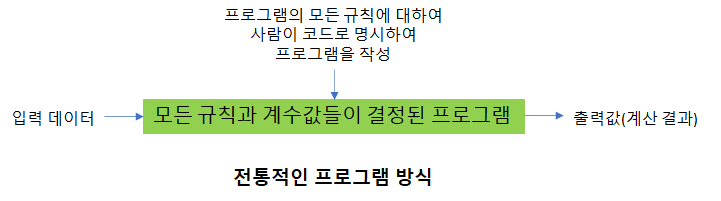
전통적인 보통의 프로그램이 모든 규칙과 계수의 값들을 프로그램 안에 명확하게 정해 주어야 하는데 반하여 기계학습 프로그래밍 방법은 규칙과 사용할 함수의 모양만을 명시적으로 결정한 프로그램을 만듭니다. 그리고 데이터셋을 가지고 훈련(Training)과정을 통하여 최선의 계수값들을 찾아냅니다. 이 과정을 통해 얻은 계수값들을 프로그램에서 불러서 새로운 데이터를 입력 받아서 결과값을 출력하는 과정을 추론(Inferencing)이라고 합니다. 기계학습 방법으로 만든 프로그램은 이렇게 훈련(Training)과 추론(Inferencing), 2단계 과정을 통하여 프로그램이 완성되는 프로그래밍 방법입니다. 이 내용을 그림으로 표현해 보면 아래와 같습니다.
기계학습 프로그램의 훈련단계
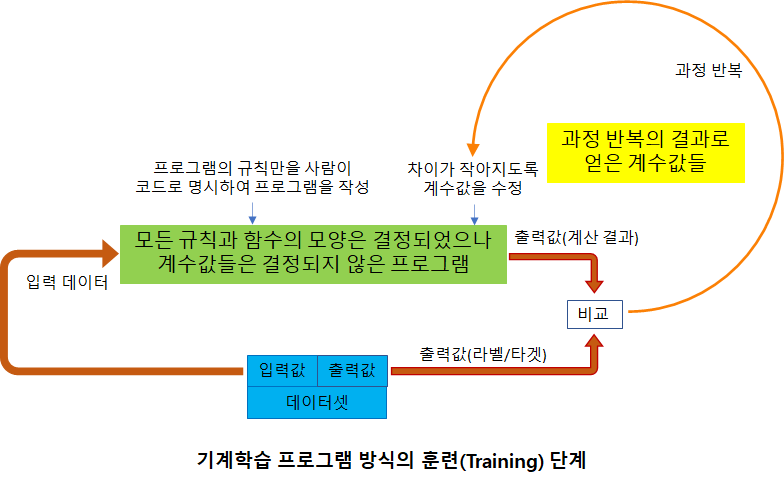
위 그림에서 처음의 계수값은 무작위로 주거나 특정한 방법에 의해 초기화합니다. 그 다음 데이터셋에 있는 입력데이터를 초기화된 계수값을 갖는 프로그램으로 계산하여 출력값을 계산하고 데이터셋에서 입력데이터와 쌍으로 있던 출력값을 꺼내서 비교합니다.
계산해서 얻은 값과 데이터셋에서 꺼내온 값의 차이가 작아지는 방향으로 계수값을 변경합니다. 이러한 작없을 전체 데이터셋에 대하여 여러번 반복하여 최적의 계수값들을 찾아내는 과정이 기계학습의 훈련단계입니다. 보통은 이런 과정을 통해 최종값으로 얻은 계수값을 별도의 파일에 저장하여 추론 프로그램과 함께 사용하게 됩니다.
기계학습 프로그램의 추론단계

위 그림은 추론단계를 보여줍니다. 훈련단계를 통하여 최적의 계수값들을 구하고 나면 이제 새로운 데이터를 입력으로 하여 원하는 결과값을 계산해 내는 프로그램을 준비해야 합니다. 이렇게 훈련을 통해 얻은 계수값을 이용하여 새로운 데이터에 대한 계산 결과를 얻는 과정을 추론이라고 하며, 이때 사용하는 프로그램을 추론 프로그램이라고 합니다.
기계학습은 궁극적으로 이 추론 프로그램을 사용하기 위한 프로그래밍 방법입니다.
이상의 내용은 기계학습을 처음 접하는 분들의 이해를 돕기 위하여 가급적 기계학습 용어를 사용하지 않았습니다. 그래서 다른 문서와 용어가 일치하지 않는 부분이 있습니다. 그러나 대략의 원리를 이해하는 데는 문제가 없다고 생각됩니다. 특히 계수값이라는 용어는 기계학습이나 딥러닝에서는 잘 사용되지 않는 용어입니다. 하지만 중고등학교 수학과정에서 계수라는 용어가 사용되는 것이라 생각되어 대부분의 사람들에게 익숙한 용어인 것 같아서 사용하였습니다. 이 점을 감안하고 보시기를 바랍니다. 기계학습과 딥러닝에 대하여 좀 더 구체적으로 다룰 때 전문용어를 적절히 사용하도록 하게습니다.
관련자료
-
다음